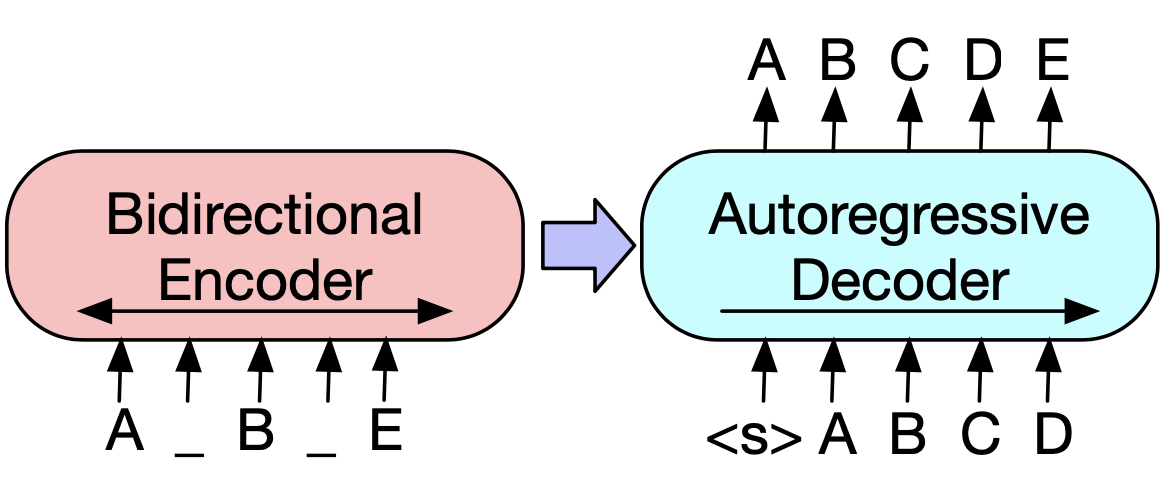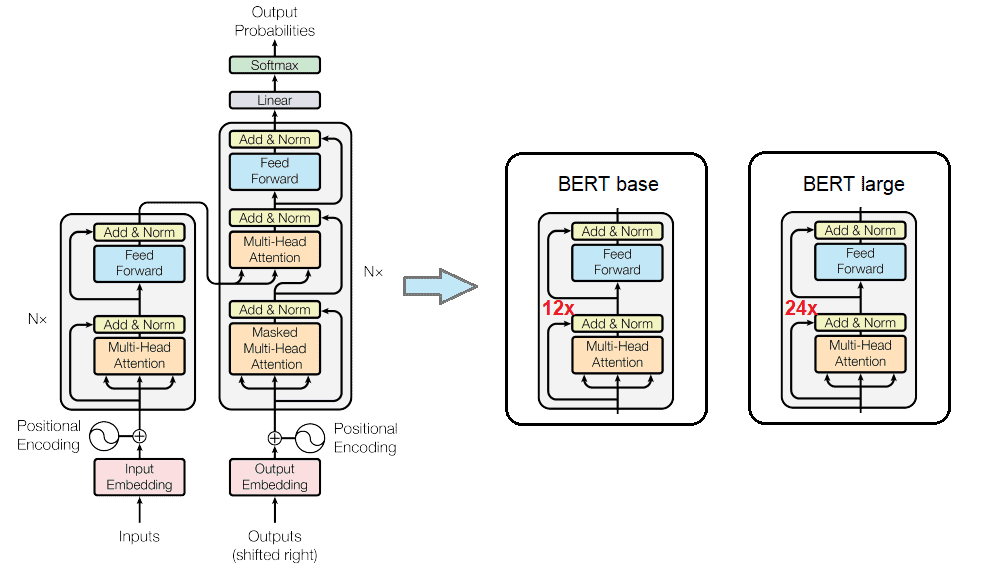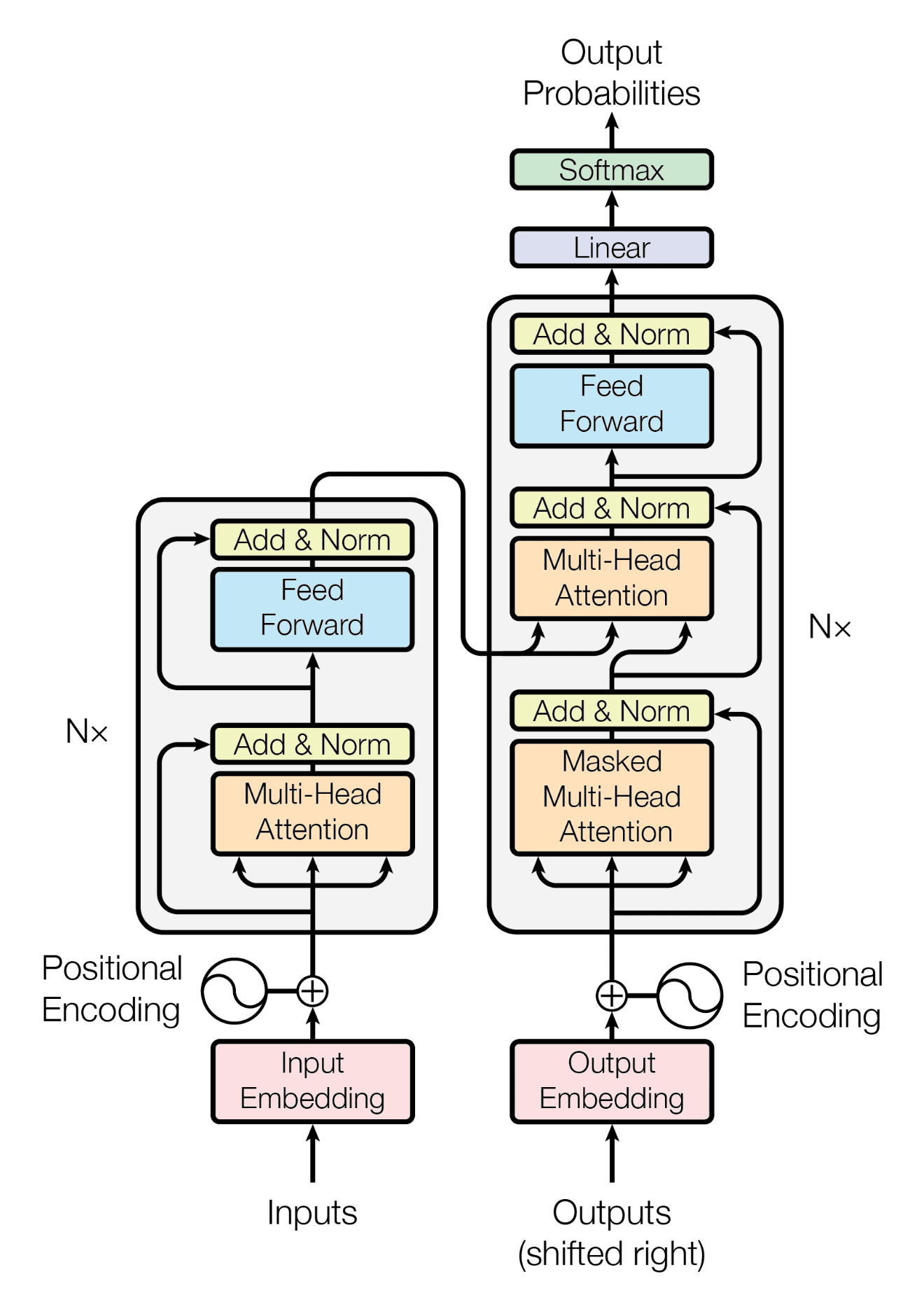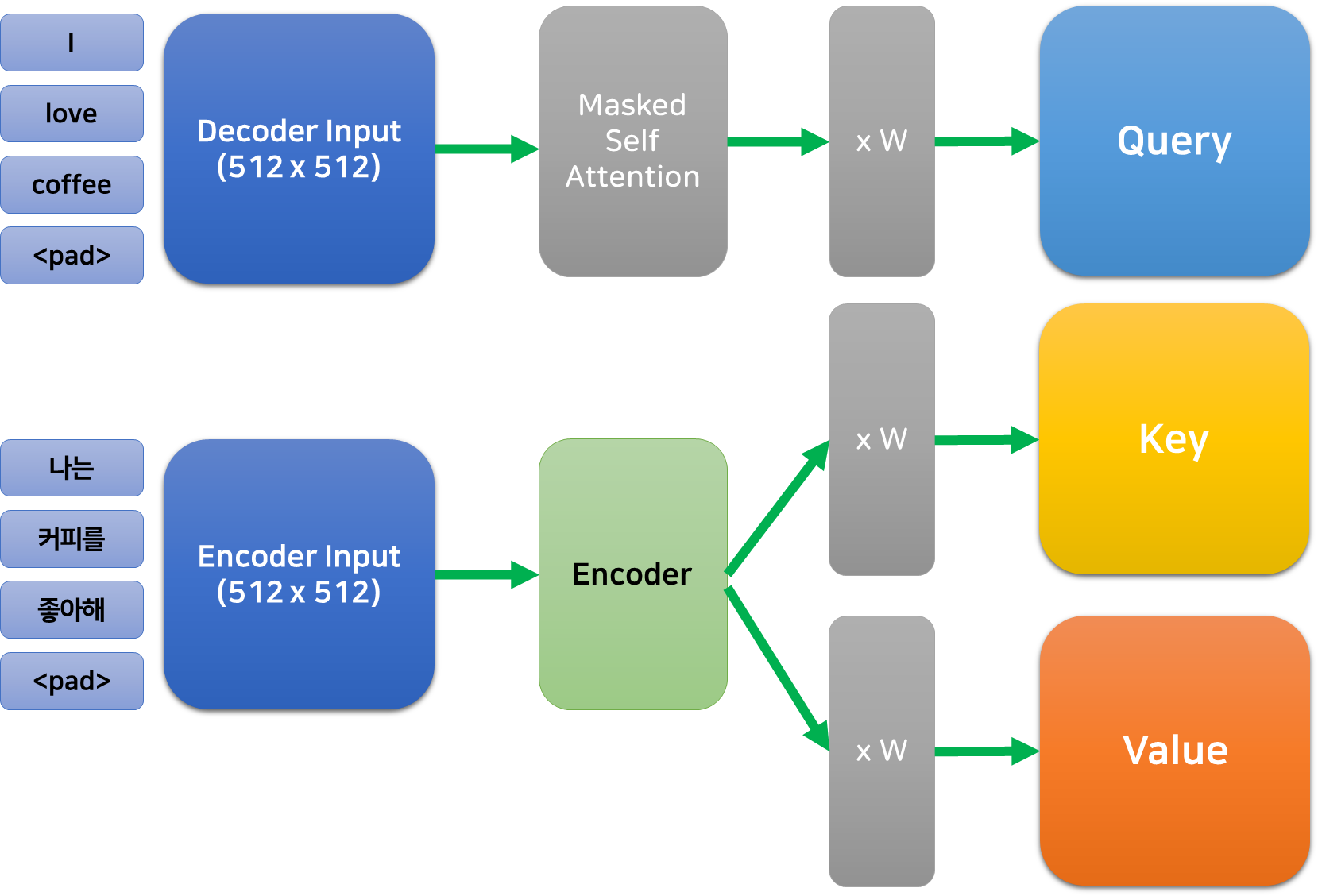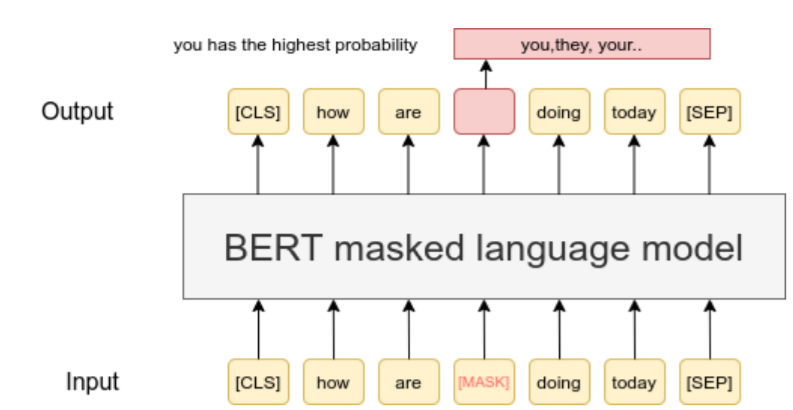
안녕하세요, 여러분! 오늘은 자연어 처리 세계의 마법 같은 기술, ‘마스크 언어 모델링(Masked Language Modeling, MLM)’에 대해 이야기해볼까 해요. 이 기술이 어떻게 우리의 일상을 바꾸고 있는지, 함께 알아보아요!
MLM, 그게 뭐예요?
마스크 언어 모델링은 마치 재미있는 단어 퍼즐 게임 같아요. 문장에서 몇 개의 단어를 살짝 가리고, 컴퓨터에게 “자, 이 빈칸에 들어갈 말은 뭘까요?”라고 물어보는 거죠. 신기하게도, 컴퓨터는 이 게임을 통해 언어를 이해하는 법을 배워갑니다.
어떻게 작동하나요?
- 먼저, 문장에서 몇 개의 단어를 살짝 가려요. 마치 스파이 영화에서 본 것처럼요!
- 그러면 컴퓨터는 주변 단어들을 살펴보며 가려진 단어를 추측해요.
- 이 과정을 계속 반복하면서 컴퓨터는 점점 더 언어를 잘 이해하게 되죠.
MLM의 장점, 정말 대단해요!
MLM이 왜 그렇게 특별한지 알아볼까요?
- 앞뒤를 모두 살펴봐요: 가려진 단어 앞뒤의 모든 단어를 고려할 수 있어요. 마치 우리가 책을 읽을 때처럼요!
- 다양한 표현을 배워요: 여러 위치의 단어를 맞추다 보니, 언어의 다채로운 표현을 자연스럽게 익히게 돼요.
- 혼자서도 잘 배워요: 특별한 설명 없이도 엄청난 양의 텍스트로부터 학습할 수 있어요. 독학의 달인이죠!
MLM, 어디에 쓰이나요?
MLM은 BERT라는 유명한 언어 모델의 핵심이에요. 이 기술로 만들어진 모델들은 정말 다재다능해요:
- 글의 주제를 파악하고
- 문장에서 사람이나 장소의 이름을 찾아내고
- 질문에 대답하고
- 글의 감정을 이해하고
- 비슷한 문장을 찾아내는 등 다양한 일을 해낼 수 있어요!
마치며
마스크 언어 모델링은 마치 마법처럼 컴퓨터가 인간의 언어를 이해하도록 만들어주고 있어요. 이 기술 덕분에 우리의 일상이 더욱 편리해지고 있죠.
여러분도 MLM의 마법을 한번 체험해보는 건 어떨까요? 어쩌면 여러분이 만든 AI가 다음번 베스트셀러 작가가 될지도 모르겠네요!
다음에 또 재미있는 AI 이야기로 찾아올게요. 그때까지 호기심 가득한 마음으로 세상을 바라보세요! 안녕히 계세요~ 👋✨