안녕하세요, 여러분! 오늘은 기업의 IT 인프라 구축에 있어 중요한 두 가지 방식인 온프레미스(On-premise)와 클라우드(Cloud)에 대해 알아보려고 합니다. 각각의 특징과 장단점을 살펴보고, 어떤 방식이 여러분의 비즈니스에 적합할지 함께 고민해볼까요?
온프레미스(On-premise)란?
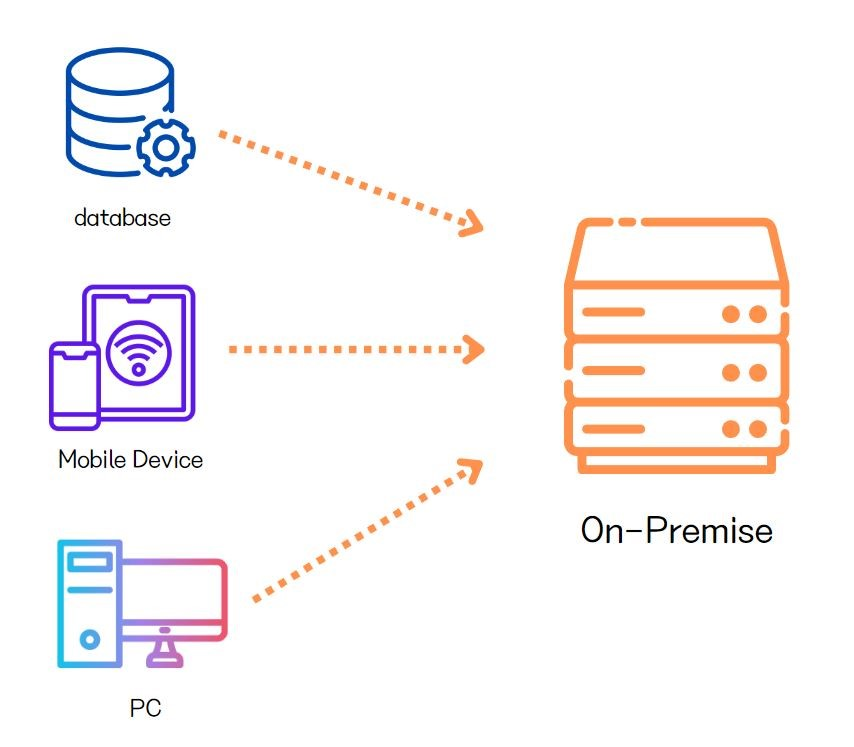
온프레미스는 기업이 자체적으로 서버, 네트워크, 스토리지 등의 IT 인프라를 구축하고 관리하는 방식입니다. 쉽게 말해, 회사 내부에 자체 서버실을 두고 직접 운영하는 것이죠.
장점:
- 높은 보안성: 데이터를 자체 관리하므로 보안 통제가 용이합니다.
- 완전한 제어: 하드웨어, 소프트웨어, 네트워크를 기업이 원하는 대로 구성할 수 있습니다.
- 맞춤형 구축: 기업의 특성에 맞는 시스템을 구축할 수 있습니다.
단점:
- 높은 초기 비용: 서버, 네트워크 장비 등 초기 투자 비용이 큽니다.
- 유지보수 부담: IT 전문 인력이 필요하며, 지속적인 관리와 업데이트가 필요합니다.
- 확장성 제한: 급격한 성장이나 변화에 대응하기 어려울 수 있습니다.
클라우드(Cloud)란?
클라우드는 인터넷을 통해 컴퓨팅 리소스를 제공받는 방식입니다. Amazon Web Services(AWS), Microsoft Azure, Google Cloud Platform(GCP) 등이 대표적인 클라우드 서비스 제공업체입니다.
장점:
- 비용 효율성: 초기 투자 비용이 적고, 사용한 만큼만 지불합니다.
- 높은 확장성: 필요에 따라 리소스를 쉽게 늘리거나 줄일 수 있습니다.
- 유연성: 언제 어디서나 접근 가능하며, 다양한 서비스를 쉽게 이용할 수 있습니다.
단점:
- 데이터 보안: 제3자에게 데이터를 맡기는 것에 대한 우려가 있을 수 있습니다.
- 의존성: 클라우드 제공업체에 대한 의존도가 높아질 수 있습니다.
- 네트워크 의존: 인터넷 연결이 불안정하면 서비스 이용에 제한이 생깁니다.
어떤 것을 선택해야 할까?
정답은 없습니다! 여러분의 비즈니스 특성, 예산, 보안 요구사항, 성장 계획 등을 종합적으로 고려해야 합니다. 최근에는 두 방식의 장점을 결합한 ‘하이브리드 클라우드’ 모델도 인기를 얻고 있죠.
중요한 것은 현재 상황을 정확히 파악하고, 미래를 예측하여 가장 적합한 방식을 선택하는 것입니다. IT 전문가와의 상담을 통해 더 자세한 조언을 받아보는 것도 좋은 방법이 될 수 있습니다.
여러분의 비즈니스는 어떤 방식이 더 적합할까요? 함께 고민해보고 최선의 선택을 하시길 바랍니다!
Citations:
[1] https://growlife.co.kr/%EC%98%A8%ED%94%84%EB%A0%88%EB%AF%B8%EC%8A%A4-%EB%9C%BB-%EC%9E%A5%EC%A0%90%EA%B3%BC-%EB%8B%A8%EC%A0%90-%EB%B0%8F-%ED%81%B4%EB%9D%BC%EC%9A%B0%EB%93%9C%EC%99%80-%EC%B0%A8%EC%9D%B4%EC%A0%90-7%EA%B0%80/
[2] https://7942yongdae.tistory.com/108
[3] https://ourbiz.tistory.com/43
[4] https://cloudedi.tistory.com/66
[5] https://www.edrawsoft.com/kr/program-review/on-premise-vs-cloud.html
[6] https://pinetreekr.tistory.com/17
[7] https://x2bee.tistory.com/407
[8] https://hyunhp.tistory.com/29
[9] https://kr.teradata.com/insights/data-architecture/on-premises-vs-cloud
[10] https://www.clunix.com/insight/it_trends.php?boardid=ittrend&mode=view&idx=606
[11] https://mblogthumb-phinf.pstatic.net/MjAyMDEwMTdfMTc5/MDAxNjAyODk2NjY1MzIz.kZJJa5LGhMYYLL7aQDUVgwRDSsdI-2RHpK8fd5eNRScg.e978zi49XlTulqz87oKEWq0uilaoKBkJ-wiyaQJD6yog.PNG.dktmrorl/onpremise.png?type=w800&sa=X&ved=2ahUKEwjPw4iWw_GKAxWgUUEAHSkCHKAQ_B16BAgKEAI
[12] https://blog.naver.com/iotspace/223195251764
[13] https://walwaldev.tistory.com/78
[14] https://www.youtube.com/watch?v=ewAYcoJwGxo